RL agents learn misaligned policies in the ALE game: Pong
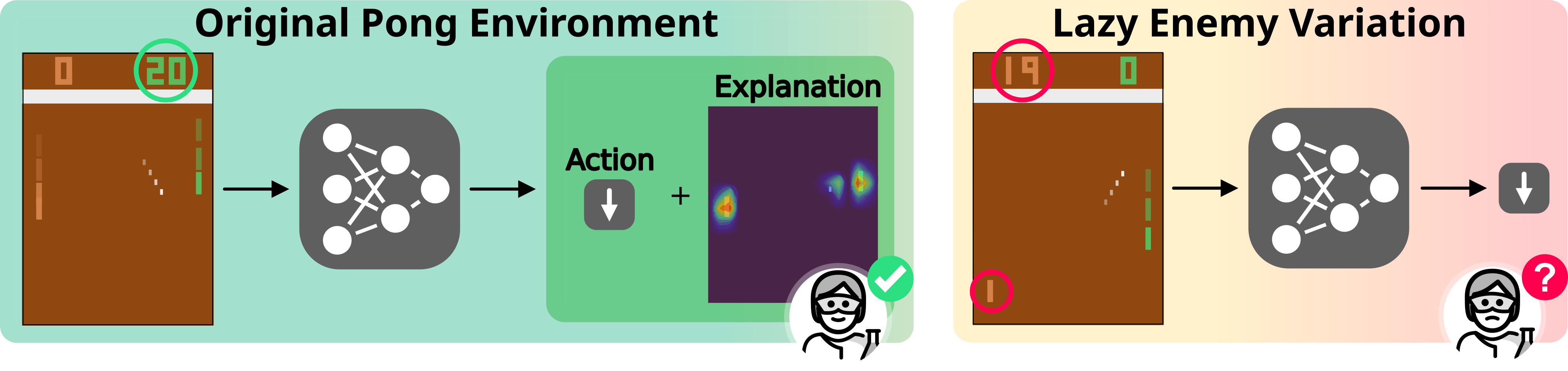
Heatmaps are not enough. Deep RL agents trained on Pong reach perfect score ✅, select the right action ✅, and exhibit intuitive importance maps. But when facing a lazier enemy, their performances drop ❌ and they select conterintuitive actions ❌.
Delfosse, Q., Sztwiertnia, S., Rothermel, M., Stammer, W., & Kersting, K. (2024). Interpretable concept bottlenecks to align reinforcement learning agents. NeurIPS.RL agents cannot generalize to tasks simplifications
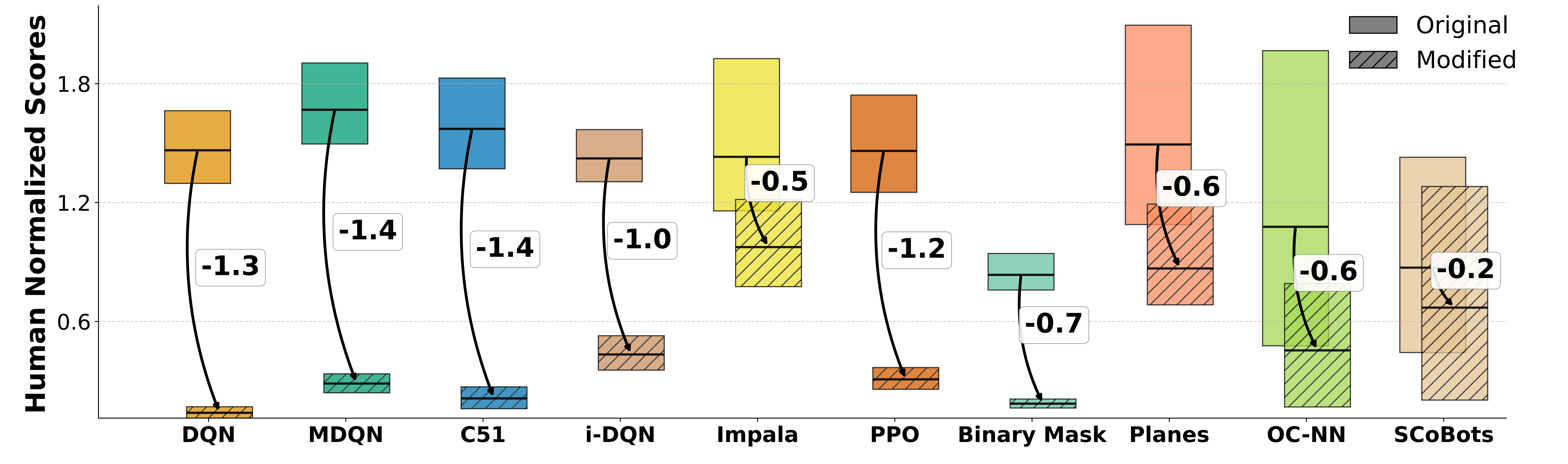
RL agents' performances drop on simplifications. Deep and current object-centric agents fail to perform well on game simplifications.
Delfosse, Q., Blüml, J., Tatai, F., Vincent, T., Gregori, B., Dillies, E., Peters, J., Rothkopf, C. & Kersting, K. (2025). Deep Reinforcement Learning Agents are not even close to Human Intelligence Under review.First order logic based policies
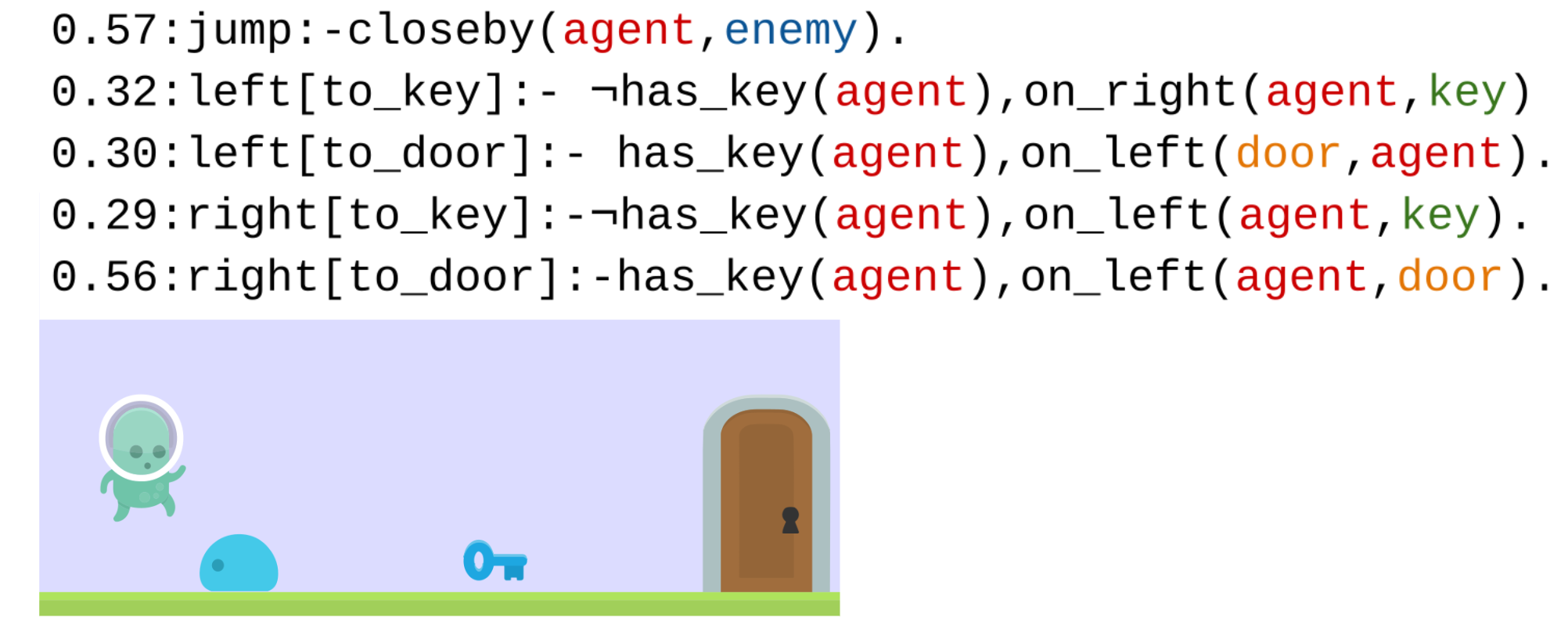
Use differentiable first order logic to encode agents' policy. Interpretable policies as a set of weighted logic rules. In this environment, the agent needs to collect a key to open a door and can jump to dodge enemies.
Delfosse, Q., Shindo, H., Dhami, D., & Kersting, K. (2023). Interpretable and explainable logical policies via neurally guided symbolic abstraction. NeurIPS.Neural/Logic mixture with LLM assisted rules generation
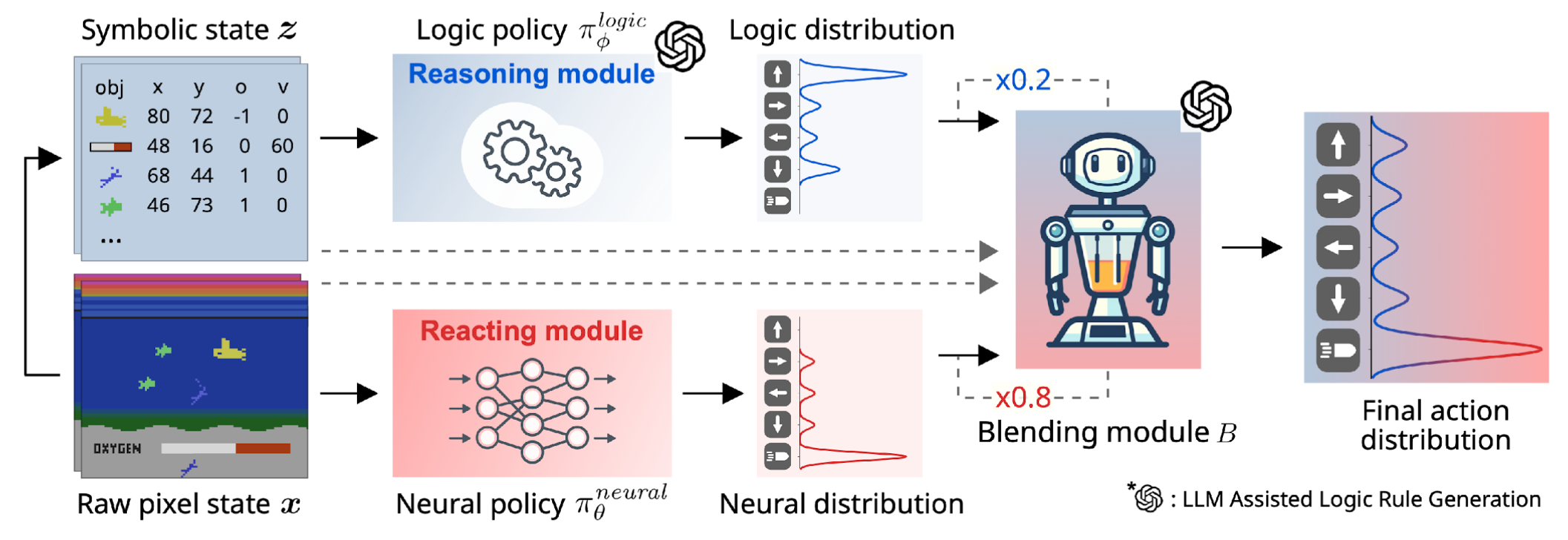
Neural and logic based agents allow to learn beyond context. An LLM is used to create an interpretable logic policy, but does not know that it can shoot enemies. To overcome this, a neural policy can takeover in threatening states.
Shindo, H., Delfosse, Q., Dhami, D., & Kersting, K. (2025). BlendRL: A Framework for Merging Symbolic and Neural Policy Learning. ICLR.